Announcing GlareDB 0.9
tl:dr> We're excited to announce v0.9.0, our second major release of 2024 that centers around GlareDB Cloud file uploads, new data sources (SQLite, Cassandra), and improved tooling for working with Excel, Lance and MongoDB.
Upload and analyze files in GlareDB Cloud
GlareDB Cloud now offers a way to analyze local files, like our CLI. CSV, JSON, and Parquet files can be uploaded to GlareDB Cloud with the click of button. All uploaded files are available in the explorer, and like all other tables in the explorer, double clicking an item produces a query for that table in the editor.
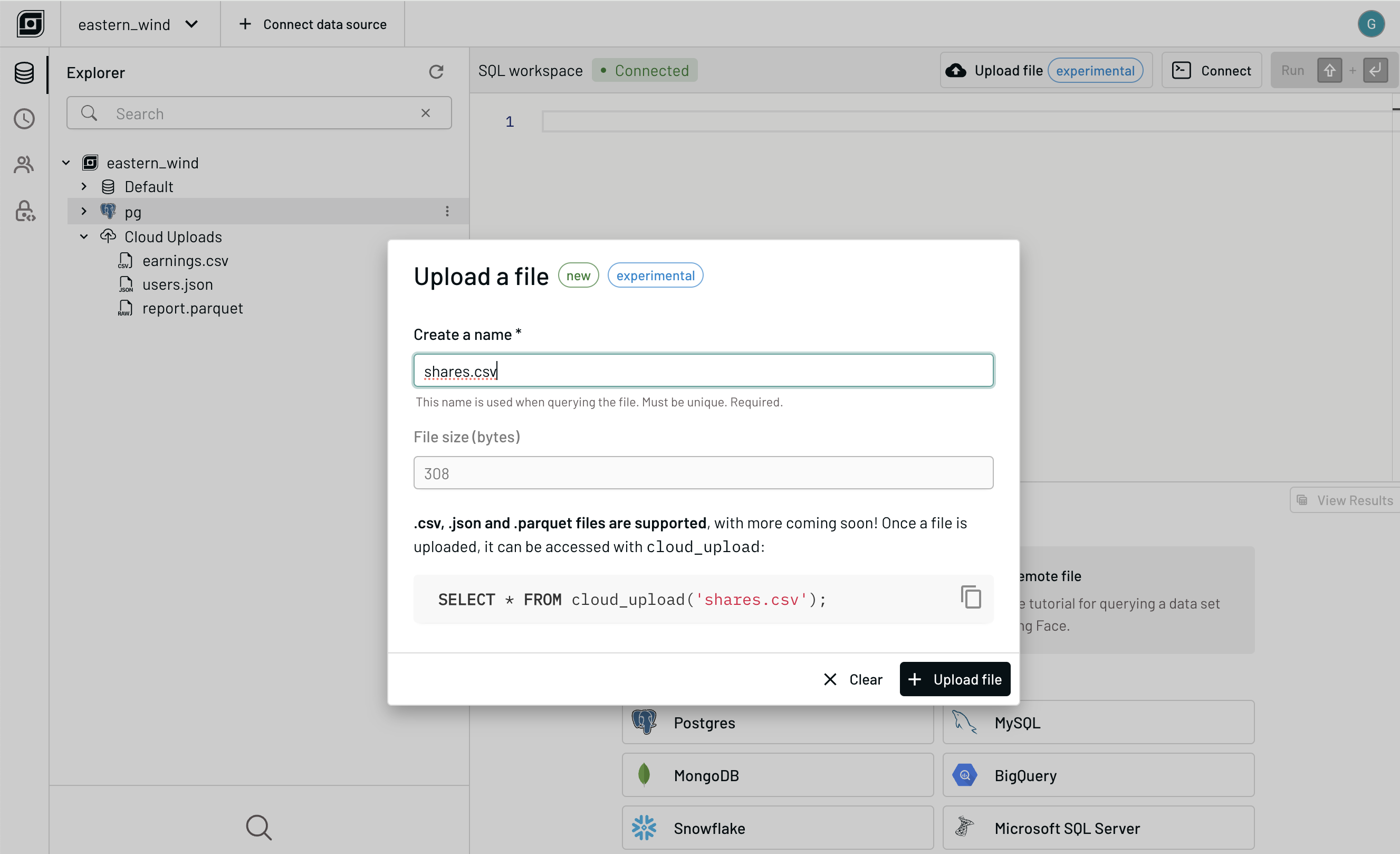
Uploaded files are accessed with a new table function: cloud_upload. This
function can be run in GlareDB Cloud:
SELECT * FROM cloud_upload('sales.csv');
We are working on adding this function to the CLI and language bindings. This feature is in an early state; we'd love to hear your input and feedback!
Data sources
In v0.8.0, support for ClickHouse was added. Since then, we've added support for SQLite and Cassandra.
SQLite
A local SQLite database can be analyzed with the GlareDB CLI or in the
Python, and Node.js bindings by adding it as a data source or using the
read_sqlite table function:
-- Add a table
CREATE EXTERNAL TABLE sl FROM sqlite OPTIONS (
location = '<location>',
table = '<table>'
);
-- Add a database
CREATE EXTERNAL DATABASE sl FROM sqlite OPTIONS (
location = '<location>',
);
-- Read a table
SELECT * FROM read_sqlite('<location>', '<table>');
In all cases, <location> is a path to a SQLite database file.
This feature is in an early state and we are looking to support SQLite file uploads and in object stores. We'd love to hear your input and feedback on use cases for SQLite!
Cassandra
A local Cassandra cluster can be analyzed with the GlareDB CLI or in the
Python, and Node.js bindings by adding it as a data source or using the
read_cassandra table function:
-- Add a table
CREATE EXTERNAL TABLE cass_tbl FROM cassandra OPTIONS (
host = '<host>',
keyspace = '<keyspace>',
table = '<table>'
);
-- Add a database
CREATE EXTERNAL DATABASE cass_db FROM cassandra OPTIONS (
HOST = '<host>'
);
-- Read a table
SELECT * FROM read_cassandra(
'<host>',
'<keyspace>',
'<table>' -- [, <username>, <password>] if using PasswordAuthenticator
);
An example host might be 127.0.01:9042 if using the default Cassandra port.
If using PasswordAuthenticator, then simply set username and password in
the OPTIONS.
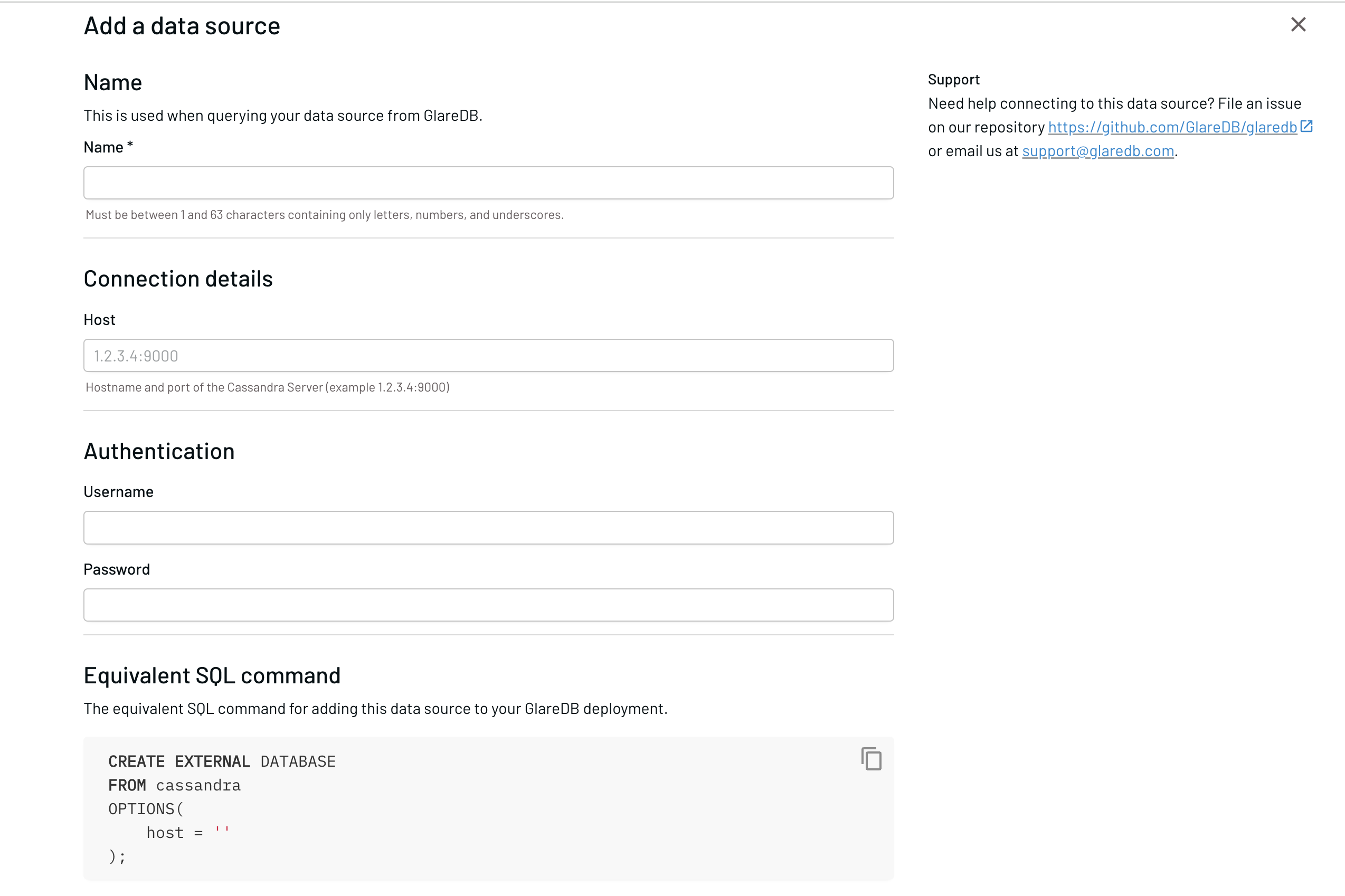
GlareDB Cloud also offers a simple form for adding a Cassandra Database that
is protected by a PasswordAuthenticator.
Excel
read_excel (or read_xlsx) now supports the following options:
sheet_name(optional, defaults to the first Sheet)has_header(optional, defaults totrue)
In the following example, events_02_2024.xlsx and users_list.xlsx are assumed to have tabular data with headers. These sheets, like any other data source in GlareDB can be gracefully joined and queried!
SELECT * FROM read_excel('events_02_2024.xlsx') events
JOIN read_excel('users_list.xlsx', sheet_name => 'paid_customers') users ON
events.id = users.event_id
We are adding support for Excel in object stores and creating external tables from Excel sheets in the near future (follow the issue here).
COPY TO
COPY TO is one of our favorite features that enables extracting, transforming
and loading data between local and remote systems with ease. In v0.9.0, we added
support for Lance tables. In the following example, the GlareDB CLI is used to
connect to GlareDB Cloud, query a Postgres table in cloud and save the results
as a Lance table locally. This is useful to enable local exploratory analysis
flows, among others.
First, create a directory for the Lance tables:
mkdir lance_explore
Then, run the GlareDB CLI and connect to GlareDB Cloud:
> glaredb --cloud-url=glaredb://<connection_string>
Connected to Cloud deployment (TLS enabled)
>
Query my_pg_table, saving the results as a Lance table in the directory
created earlier:
COPY (
SELECT * FROM my_pg_table
WHERE col_a > 200
)
TO './lance_explore' FORMAT lance;
Inserts
We are incrementally adding insert support to all appropriate data sources (follow the issue here), to support data flowing in both directions.
This release added support for inserts to MongoDB:
CREATE EXTERNAL TABLE m FROM mongo OPTIONS (
connection_string = '<connection_string>',
database = '<database>',
collection = '<collection>',
);
ALTER TABLE m SET ACCESS_MODE TO READ_WRITE;
INSERT INTO m (a, b, c) VALUES (1, 2, 3);
and Lance tables:
CREATE EXTERNAL TABLE l FROM lance OPTIONS (
location '<location>'
);
ALTER TABLE l SET ACCESS_MODE TO READ_WRITE;
INSERT INTO l (a, b, c) VALUES (1, 2, 3);
Table functions
A new, experimental table function read_json was added that can read
array and multi-line JSON:
SELECT * FROM read_json('./users.json')
This function is limited in scope to presently read the first object from a data source (an array or one-row-single document), and can be used to read data dumps or data from public APIs.
Sign up for GlareDB Cloud with GitHub
We love developing OSS Glaredb on GitHub and often using GitHub for authentication with other tools. So a short while ago we added Github sign-in to GlareDB Cloud.
If you've been enjoying GlareDB CLI, Python, or Node.js bindings, GlareDB Cloud offers a free tier to scale up those workflows. By signing up, a fully-managed deployment with 10 GB of storage is created for you. By adding your data sources to GlareDB Cloud, you bring all your data with whatever client or tool you connect with. This includes the aforementioned CLI and bindings, but also Postgres-compatible clients and dashboard and reporting tools for visualizing data.
Sign up at https://console.glaredb.com/signup!
It's been an exciting month since v0.8.0 - we've been adding new data sources and interfaces to make interacting with your data sources easier. For our next major release, we are working on expanding support for data sources (Iceberg, Excel and Google Sheets) and integrating with your existing data tooling like dbt. We're also working on expanding vector search and AI features to make our Lance support even more useful, especially in ML and Vector-based use cases. We're also making strides in improving the execution engine behind it all to make things faster and more reliable. Broadly, these efforts are Distributed Execution, improving how queries are pushed down and federated, and further optimizations to the engine.
Here are a few issues to follow for features we anticipate landing in the next major release:
- Excel data sources: https://github.com/GlareDB/glaredb/issues/1994
- Google Sheets: https://github.com/GlareDB/glaredb/issues/2604
- Iceberg support: https://github.com/GlareDB/glaredb/issues/1448
For a broader view of our roadmap, refer to GlareDB Roadmap 2024.
What else would you like to see? Let us know! You can set up a chat or email us at hello@glaredb.com.