Hybrid Execution: Scale your workflow with GlareDB Cloud
We're building GlareDB to query your data, wherever it is. Your data may be on
your laptop, in other databases or in the cloud. It may exist as Parquet, CSV or
JSON formats. Regardless, 100% of the time there are multiple steps across
several destinations in getting to the end result you need. Now with
Hybrid Execution, you can SELECT and JOIN all of your data with SQL you
already know.
Typically, your data exists both locally and in the cloud, especially while developing and experimenting. Hybrid Execution allows you to combine local and remote data efficiently by using both your local machine and cloud resources. During query execution, GlareDB splits the query into separate pieces to run remotely or locally. Some queries may be run entirely locally, remotely, or a combination based on efficiency in query planning.
Get started with Hybrid Execution
GlareDB Cloud offers a free tier for getting started with Hybrid Execution. When you sign up, we automatically spin up a deployment for you with 10 GB of storage. You will arrive at our web-based SQL workspace where you can begin querying and working with GlareDB immediately.
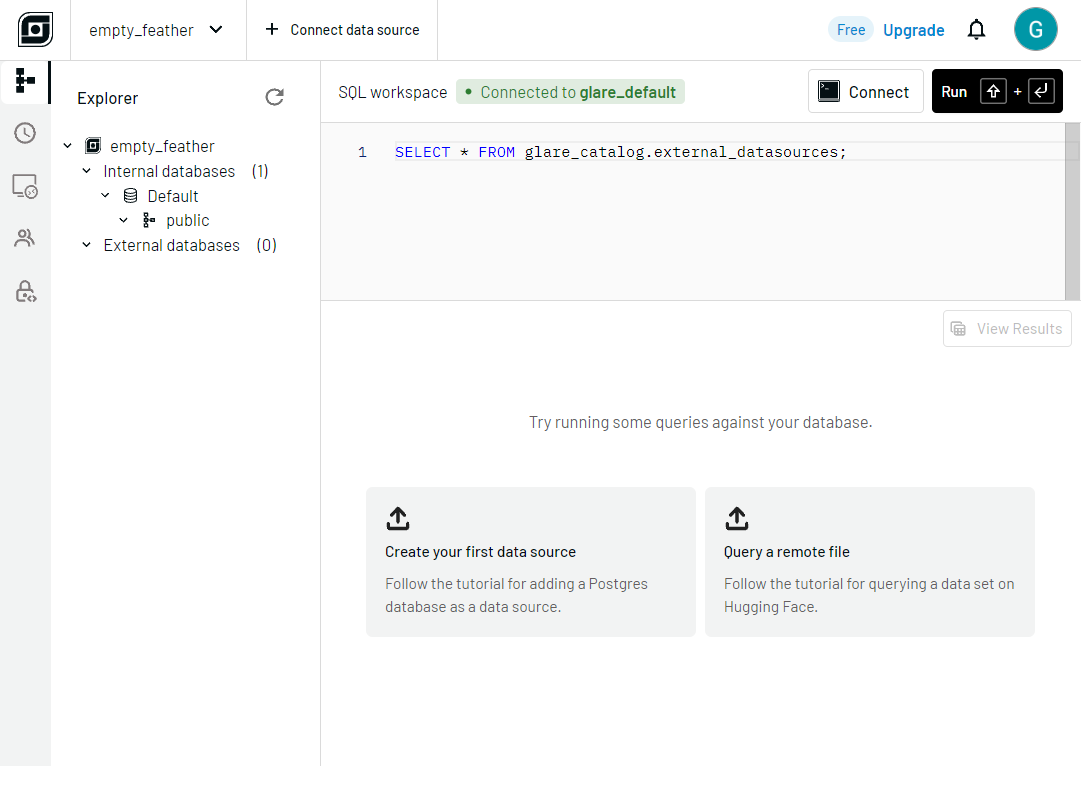
By clicking the Connect button in the top right, we provide a simple command that you can copy and use when running GlareDB locally.
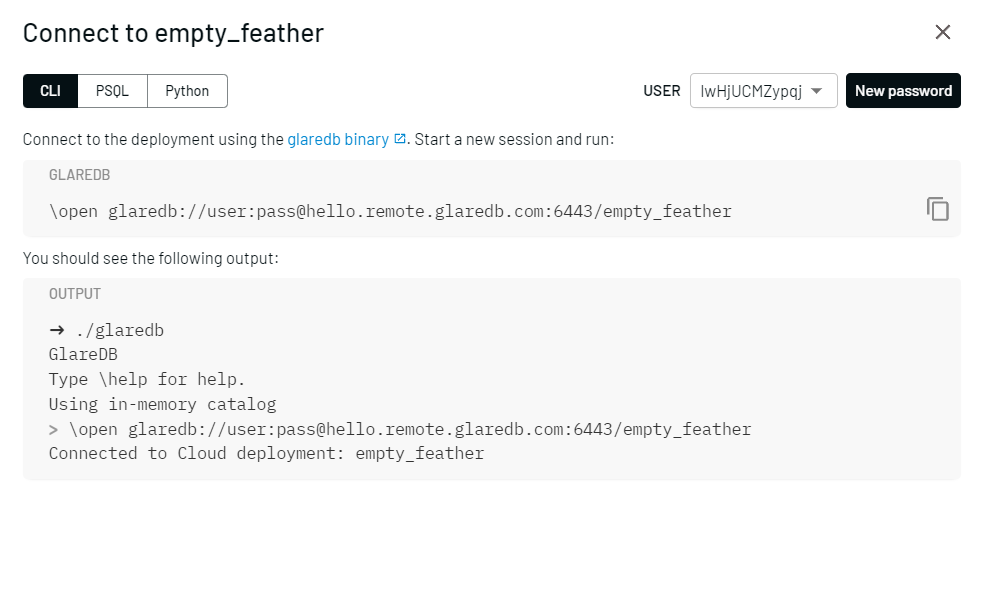
If you don't have GlareDB installed or haven't updated to 0.5.0 yet, simply run the following in the directory where you would like to install or update the GlareDB binary:
curl https://glaredb.com/install.sh | sh
Then, simply paste the connection command from GlareDB Cloud in the GlareDB CLI:
./glaredb
\open glaredb://user:pass@hello.remote.glaredb.com:6443/empty_feather
At this point, GlareDB is running locally on your machine and is additionally connected to your GlareDB Cloud deployment. You are ready to combine data from from the deployment as well as process local files.
Hybrid Execution in action
As an example, imagine you have a CSV on your local filesystem containing a single column of user IDs. The CSV might look like the following:
id
cd67387e-3d37-4803-850a-ff2f2d913261
7bd25c6f-c394-4cf7-9715-a5e9cc138bcd
7e168af4-7c77-4d80-90ea-17677ca9de81
0720b2cc-3906-4d7d-a822-33ead2387797
265448e5-35d9-418e-9114-c4b948abdf30
1a04aef1-a458-4b78-9953-6b90e752837b
Futhermore, imagine there's a table in your cloud deployment called user_metrics
that stores entries containing a user ID, and number of output_rows per
entry.
You can efficiently join this data on your local machine using familiar SQL:
SELECT
m.user_id,
max(m.output_rows),
avg(m.output_rows)::int
FROM
user_metrics m
INNER JOIN './company_users.csv' u on m.user_id = u.id
GROUP BY m.user_id
LIMIT 5;
┌──────────────────────────────────────┬────────────────────┬────────────────────┐
│ user_id │ MAX(m.output_rows) │ AVG(m.output_rows) │
│ ── │ ── │ ── │
│ Utf8 │ Int64 │ Int32 │
╞══════════════════════════════════════╪════════════════════╪════════════════════╡
│ 7bd25c6f-c394-4cf7-9715-a5e9cc138bcd │ 13575 │ 78 │
│ 0720b2cc-3906-4d7d-a822-33ead2387797 │ 1000000 │ 302 │
│ 7e168af4-7c77-4d80-90ea-17677ca9de81 │ 11000000 │ 1229 │
│ cd67387e-3d37-4803-850a-ff2f2d913261 │ 10000 │ 64 │
│ 265448e5-35d9-418e-9114-c4b948abdf30 │ 1847746 │ 4858 │
└──────────────────────────────────────┴────────────────────┴────────────────────┘
In this query, we are able to provide a relative path ./company_users.csv
while referencing the user_metrics table residing in the cloud deployment
without any additional syntax. GlareDB can understand how to query the CSV file
locally while joining and remotely processing data from user_metrics.
Hybrid Execution in Python
Hybrid Execution also works with the GlareDB Python library. Like the prior example, paste the Python connection string from GlareDB Cloud.
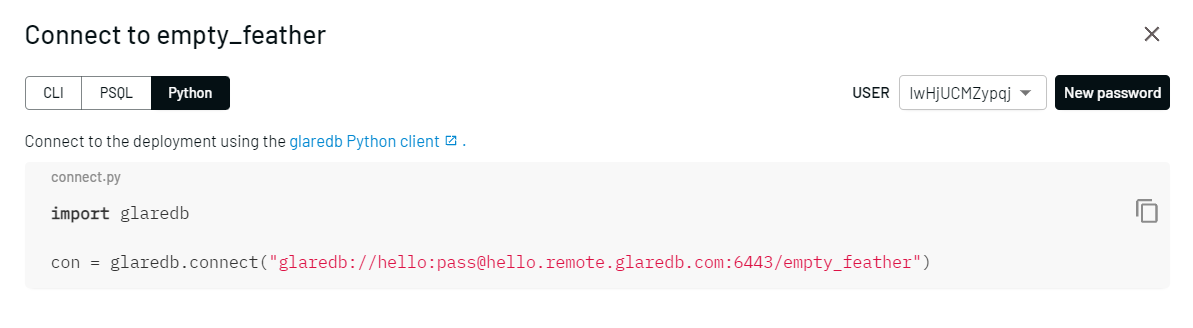
We can run the same query (including scanning a local file) from Python. We can also interop with DataFrames from Pandas or Polars. We'll adapt the above example with Pandas:
import glaredb
import pandas as pd
con = glaredb.connect("glaredb://user:pass@hello.remote.glaredb.com:6443/empty_feather")
company_users = pd.DataFrame(
{
"id": [
"cd67387e-3d37-4803-850a-ff2f2d913261",
"7bd25c6f-c394-4cf7-9715-a5e9cc138bcd",
"7e168af4-7c77-4d80-90ea-17677ca9de81",
"0720b2cc-3906-4d7d-a822-33ead2387797",
"265448e5-35d9-418e-9114-c4b948abdf30",
"1a04aef1-a458-4b78-9953-6b90e752837b"
]
}
)
con.sql("""
SELECT
m.user_id,
max(m.output_rows),
avg(m.output_rows)::int
FROM
execution_metrics m
INNER JOIN company_users u on m.user_id = u.id
GROUP BY m.user_id
LIMIT 5;
""").show()
┌──────────────────────────────────────┬────────────────────┬────────────────────┐
│ user_id │ MAX(m.output_rows) │ AVG(m.output_rows) │
│ ── │ ── │ ── │
│ Utf8 │ Int64 │ Int32 │
╞══════════════════════════════════════╪════════════════════╪════════════════════╡
│ 7bd25c6f-c394-4cf7-9715-a5e9cc138bcd │ 13575 │ 78 │
│ 0720b2cc-3906-4d7d-a822-33ead2387797 │ 1000000 │ 302 │
│ 265448e5-35d9-418e-9114-c4b948abdf30 │ 1847746 │ 4858 │
│ 1a04aef1-a458-4b78-9953-6b90e752837b │ 60175 │ 1468 │
│ cd67387e-3d37-4803-850a-ff2f2d913261 │ 10000 │ 64 │
└──────────────────────────────────────┴────────────────────┴────────────────────┘
A look ahead: Compute and storage at scale
GlareDB Cloud is free and designed for getting started with Hybrid Execution so that you can scale your local data development workflows. When you upgrade your GlareDB Cloud account, you gain access to:
- Unlimited storage
- Dedicated compute (billed on usage)
Compute engines are customizable and cost-effective cloud compute nodes that can be scaled or powered off to suit your needs.
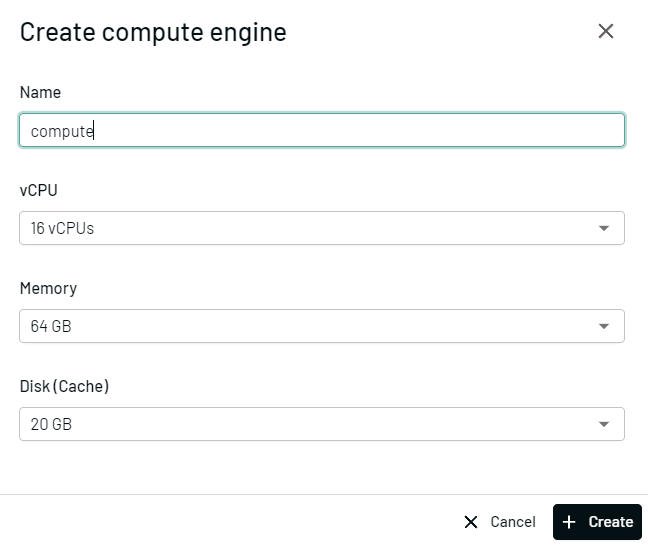
You can utilize compute engines in Hybrid Execution as well as our web-based SQL workspace, depending on your use case.
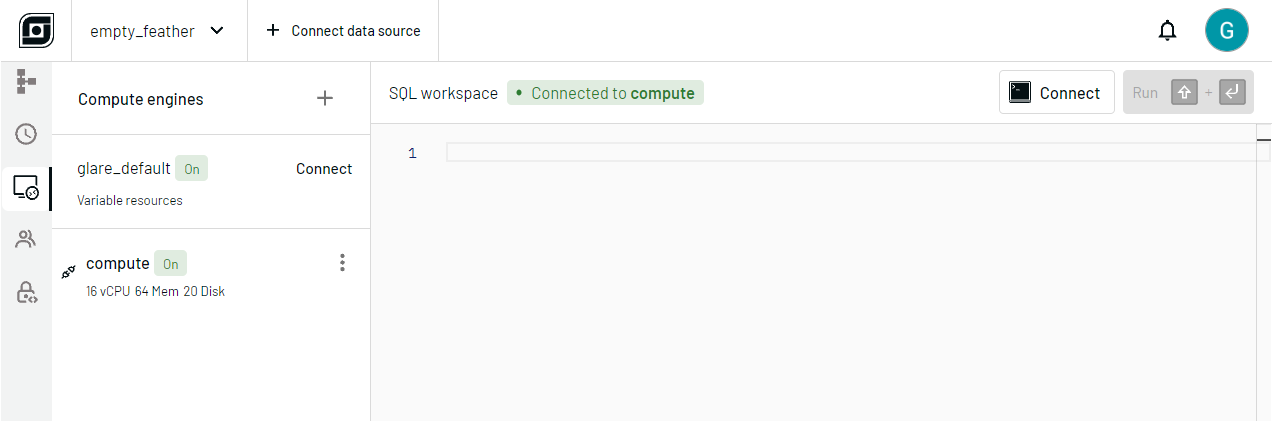
To use a compute engine with Hybrid Execution, simply specify it in the
connection string. From the previous example, simply qualify the deployment
name (empty_feather) with the name of the engine, compute:
\open glaredb://user:pass@hello.remote.glaredb.com:6443/compute.empty_feather
Data everywhere made easy
Our goal with GlareDB is to reduce time to insight. At a processing level, we accomplish this is with our performant engine built in Rust with DataFusion. At a human level, we design our interfaces to be simple and familiar. There's no need to learn new tools or frameworks: just query your data wherever it lives with SQL you already know.
See for yourself just how easy it is to query a CSV hosted on Hugging Face.
Try it out:
# install or update GlareDB
curl https://glaredb.com/install.sh | sh
# query
./glaredb --query "SELECT * FROM \
'https://huggingface.co/datasets/fka/awesome-chatgpt-prompts/raw/main/prompts.csv';"
Hybrid Execution advances our mission by enabling you to join cloud data with local data seamlessly.
We look forward to hearing your feedback. Hit a bug, or have an idea on how to make this even better? Let us know by opening up an issue in our repo.