Announcing GlareDB's NodeJS Bindings
tl;dr> GlareDB now provides JavaScript bindings. These, like the Python bindings, provide a complete embeddable GlareDB instance that you can use from within your JavaScript codebase, in addition to hybrid and fully-remote execution with GlareDB Cloud.
This post is accompanied by the nodejs-bindings-example repository. To run the examples, fork, download or clone the repository.
Getting Started
The bindings are in the glaredb package, which you can install from npm:
npm install @glaredb/glaredb
You can run the bindings in JavaScript, or TypeScript (types are provided):
import glaredb from "@glaredb/glaredb"
const conn = await glaredb.connect()
const res = await conn.sql(
`SELECT
id,
username,
score
FROM './students.csv'
WHERE active = true`
)
await res.show()
By calling connect() without any arguments, we create a connection to the
local GlareDB instance, which is just the embedded database. This query parses
a CSV file (students.csv) and extracts a few fields for rows where "active" is
true, and prints them in a tabular format. You can call toArrow() or
toPolars() instead of show() to resolve the results in one of these formats.
The sql() method is lazy for queries that select data, but eager for queries
that modify data so the query isn't run until you resolve the results.
Connecting to GlareDB Cloud
In the GlareDB Cloud dashboard, click "Connect", select the "Node.js" tab and copy the connection string.
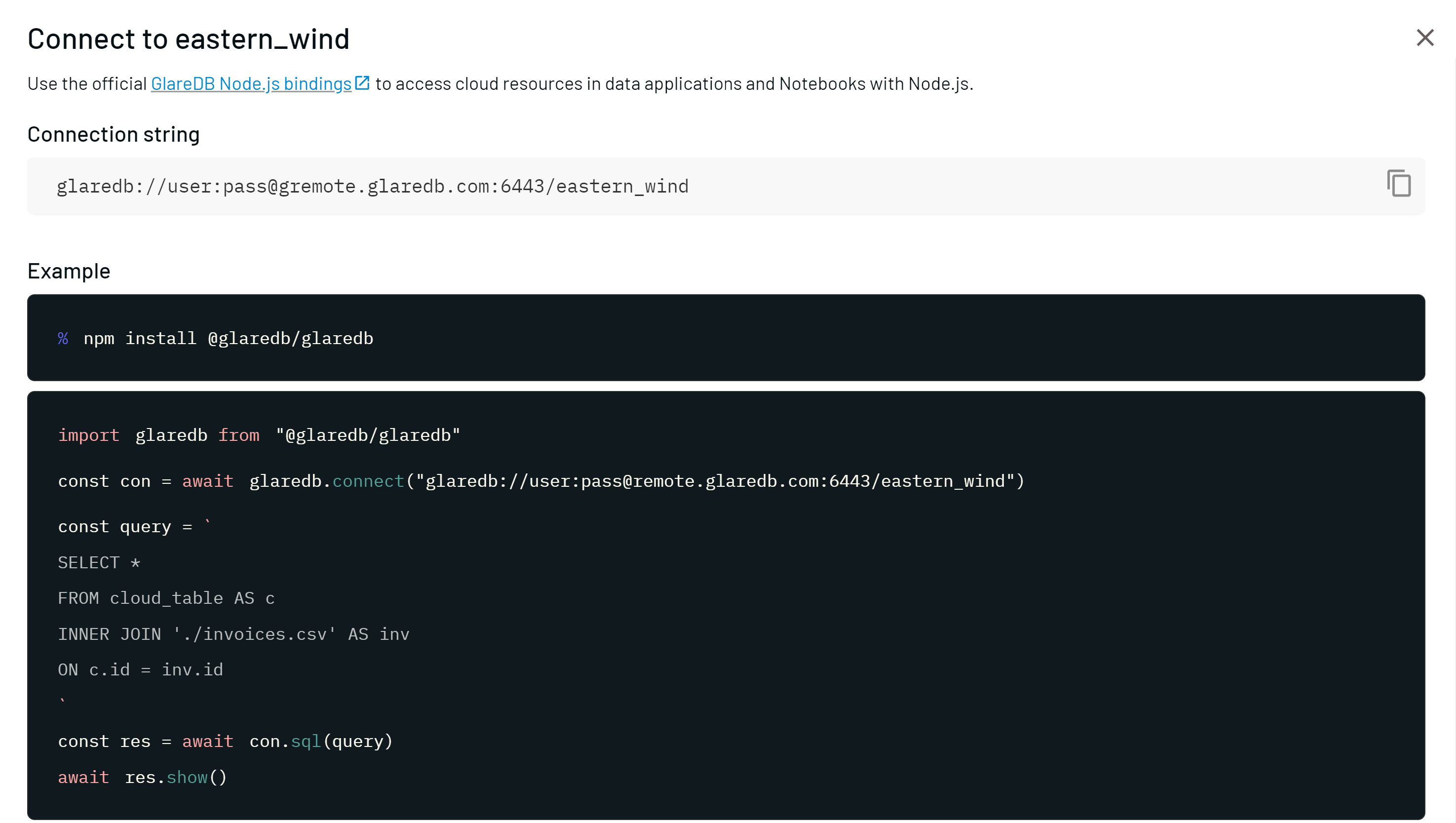
Back in JavaScript, simply pass the string to connect():
const conn = await glaredb.connect("glaredb://your-connection-string")
This connection can now access both local and remote data. In addition, queries are optimized to use local and cloud compute resources with Hybrid Execution.
Add data sources so that you can access your data in
operational data stores and data warehouses in addition to
data in local files. This means you can JOIN data from PostgreSQL and/or
Excel, CSV, Parquet, or JSON sources, without any extra dependencies or setup.
In the nodejs-bindings-example, we demonstrate joining local CSV data with Postgres:
const conn = await glaredb.connect(cloudURL)
const res = await conn.sql(`
SELECT
c.c_custkey,
c.c_name,
c.c_acctbal,
r.projection
FROM my_pg.public.customer c
INNER JOIN './customer_report.csv' r
ON c.c_custkey = r.cid;
`)
await res.show()
In this example, my_pg.public.customer is a Postgres data source in GlareDB
Cloud called my_pg. The table public.customer is joined with CSV data in
the local filesystem (customer_report.csv).
Putting a data warehouse or data catalog inside your application, wherever it runs is pretty neat and can simplify a lot of your application: no more boiler plate for parsing well-known formats, no more implementing filtering and aggregation yourself; just write a SQL statement and let GlareDB do the rest.
There are two ways to use GlareDB Cloud: In Hybrid Execution, your local embedded database is in control. Only some of the computations - the operations that access remote data sources - run in the cloud while the remaining work involving local data sources and the final aggregation runs locally. In Cloud Execution, all of the execution runs remotely and GlareDB manages and tracks your remote data sources. This way you can use the same GlareDB resources from multiple copies of a distributed application, and all of the data can live in the cloud.
Please give it a try and tell us what you think!